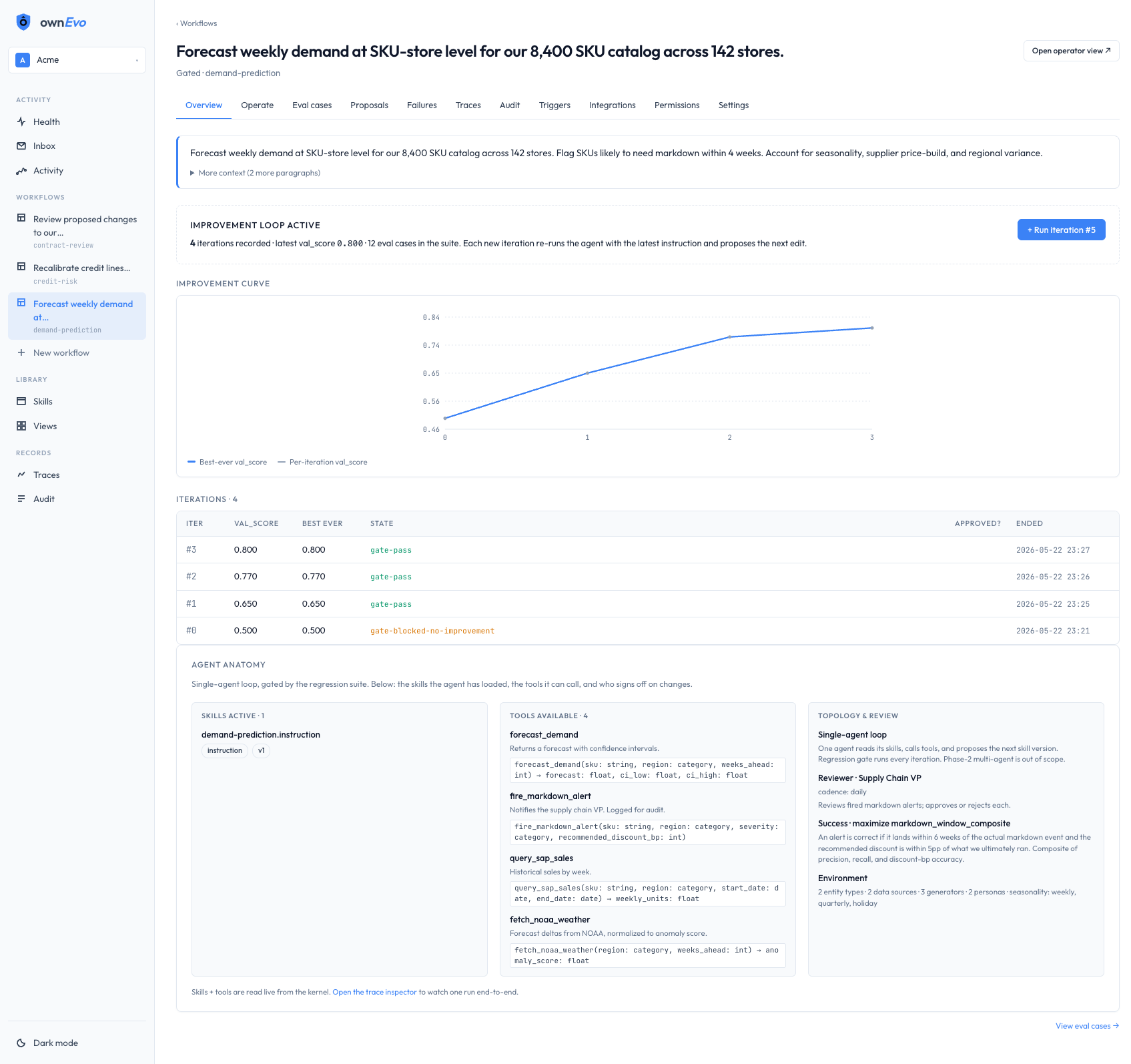
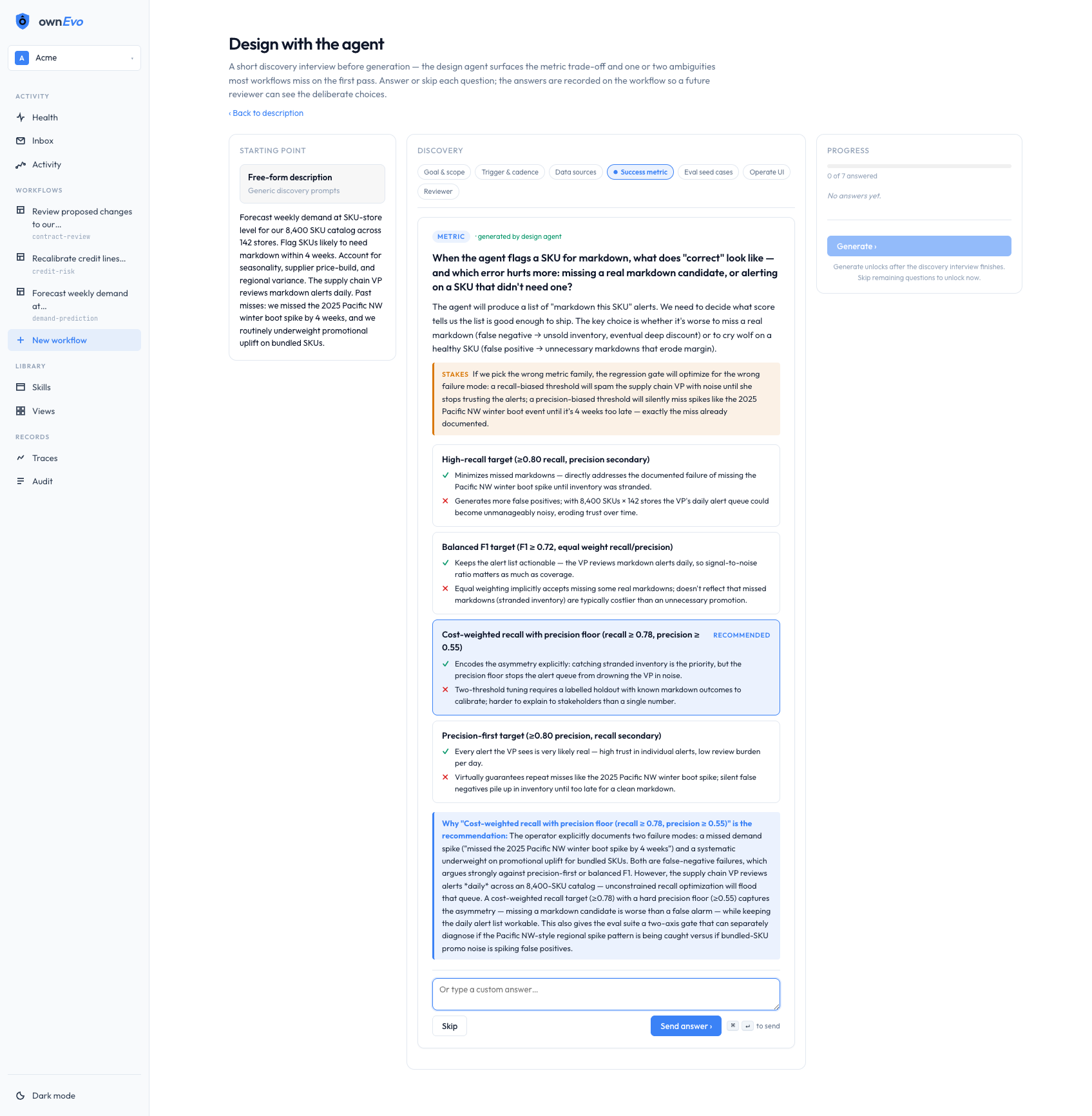
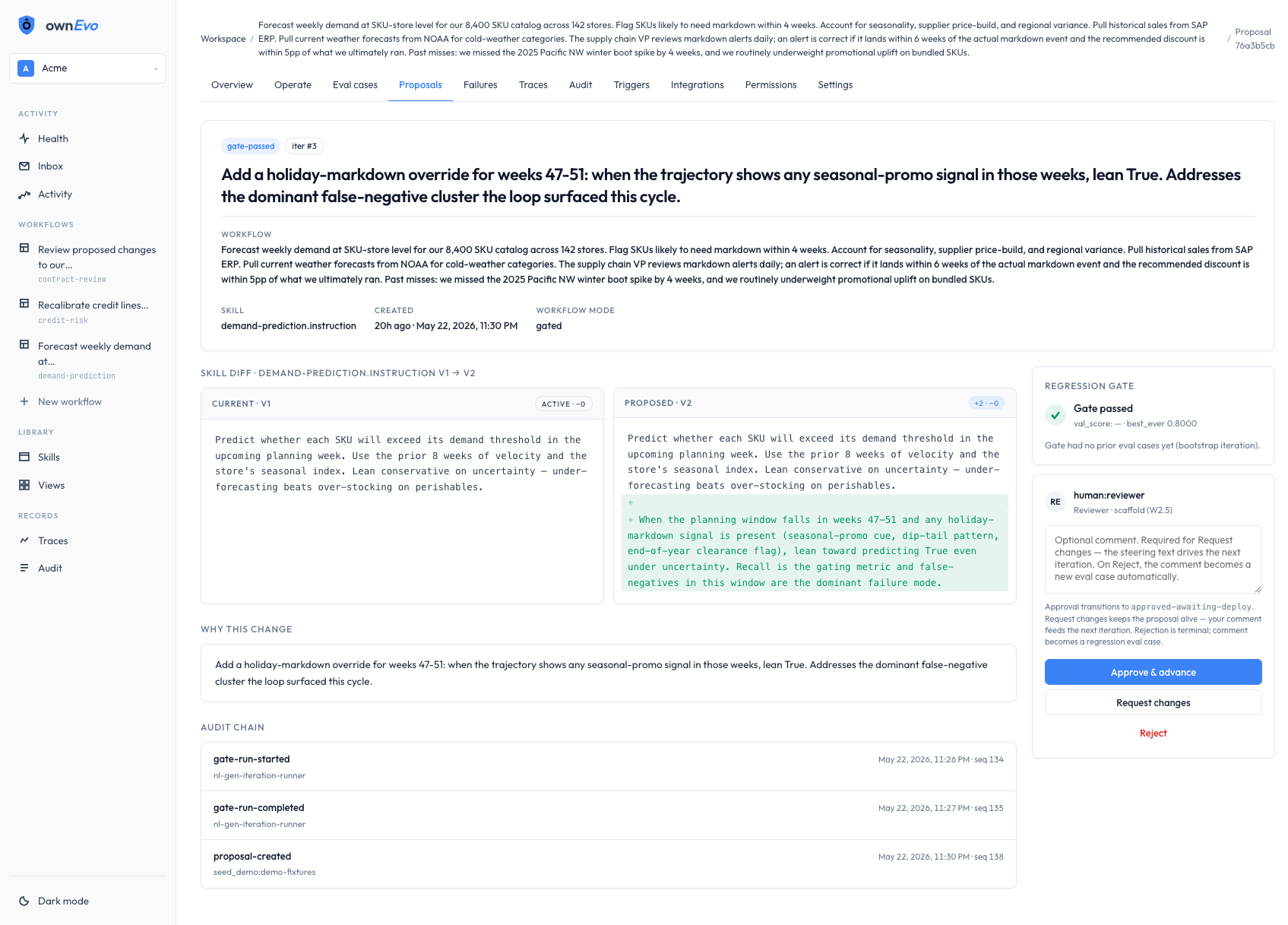
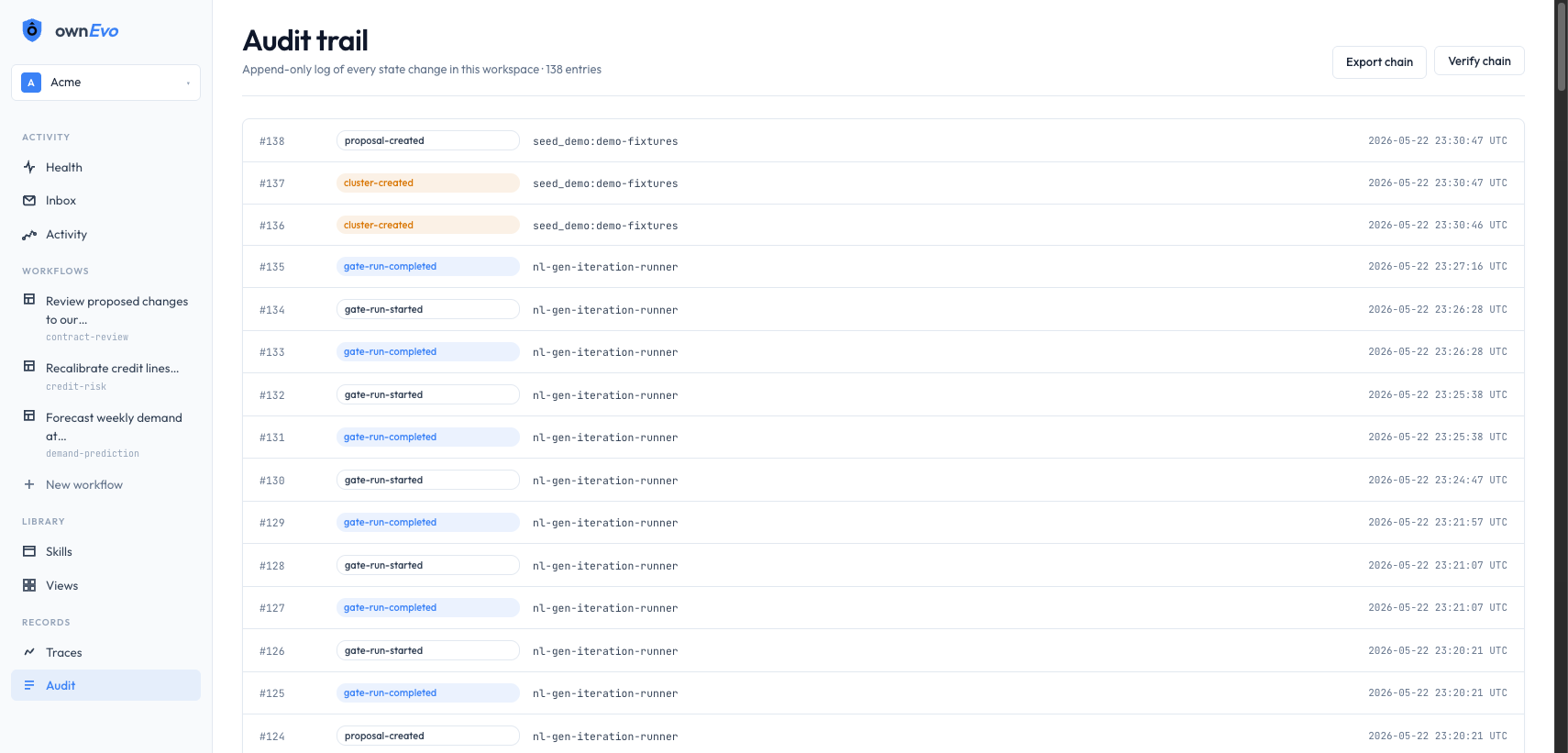
What the domain expert opens on Monday
Four screens. Real data. No mockups.
Captured live from the running system. The same surfaces your domain expert touches every cycle. Click any image to enlarge.
Try the live demo
Source on GitHub. Self-host in one command.